
Case Study: Business Data Management
The case study which follows describes an example in which a Data Management Layer has been introduced to Newcastle University. The example illustrates that adding a Data Management Layer need not be a disruptive process. It can be achieved incrementally and can produce immediate benefits which encourage further progress.
Business Data Management
Many organisations obtain similar or related data from multiple sources. This can result in different data sets, purporting to hold the same information, being utilised in independent silos. Where the information held in the data sets differs, this can lead to inconsistencies and inefficiencies within the organisation. The fact that data is locked within silos frequently prevents the organisation from correcting, or even detecting, these problems when they arise.
Newcastle University, in common with many organisations, collects information on the organisations with whom it engages (or would like to engage with) from many different sources. In the case of Newcastle University, sources include data provided by the University’s Business Engagement teams, data collected from surveys and events, and data purchased from Companies House and from commercial Business Data providers. All of these sources can contain invalid information. Even Companies House data, often considered the ‘gold’ standard, can be out-of-date or incorrect due to data entry problems.
The use of the different sources by the different applications utilised by different departments can be problematic. For example: a Business Engagement team might deal effectively with an organisation but the Careers team might hold an invalid address for that organisation and therefore fail to effectively coordinate their engagement; one department might engage with ‘J. Jones and Sons’ and another with ‘John Jones Ltd’ without realising that these are the same business.
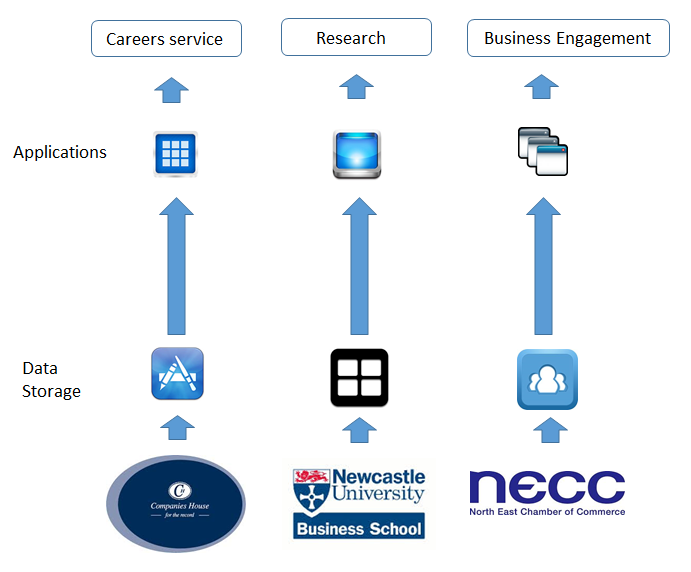
Identifying these types of inconsistency is a notoriously difficult problem, made well-nigh impossible by the existence of siloed information as data is collected independently, and is held and output in different formats. Even where inconsistencies are spotted, often following a problem having arisen, correcting the data is a manual, error-prone process which needs repeating again and again each time new data is ingested.
Newcastle University turned to Arjuna Technologies for help.
Agility DataBroker
Arjuna Technologies have created their Agility DataBroker product to act as a Data Management layer in just such a scenario. The project team wanted to proceed carefully with minimum disruption to the various teams, so as a first step introduced Agility DataBroker as a means of holding copies of the data collected by each independent system. To do so they created a plug-in for Agility DataBroker which was capable of obtaining the data from the existing Data Storage systems. They then created a set of Agility DataBroker plug-ins capable of analysing the data and outputting a ‘Data Inconsistency Report’ identifying any inconsistencies discovered. This report could be used by University teams to assist them in correcting their data sources, or in making allowances for the inconsistencies within their internal processes. Note that the report (or a version of it) could be delivered to the organisation from which the original data was obtained, allowing them to clean the data themselves. For example during this project it became apparent that there were significant errors in the NECC data (generally created by transcribing data from paper forms). The report generation was implemented as an automated process so that the ingestion of new versions of any of the data sources could generate a new report. An interim architecture after the introduction of the Agility DataBroker is illustrated below.
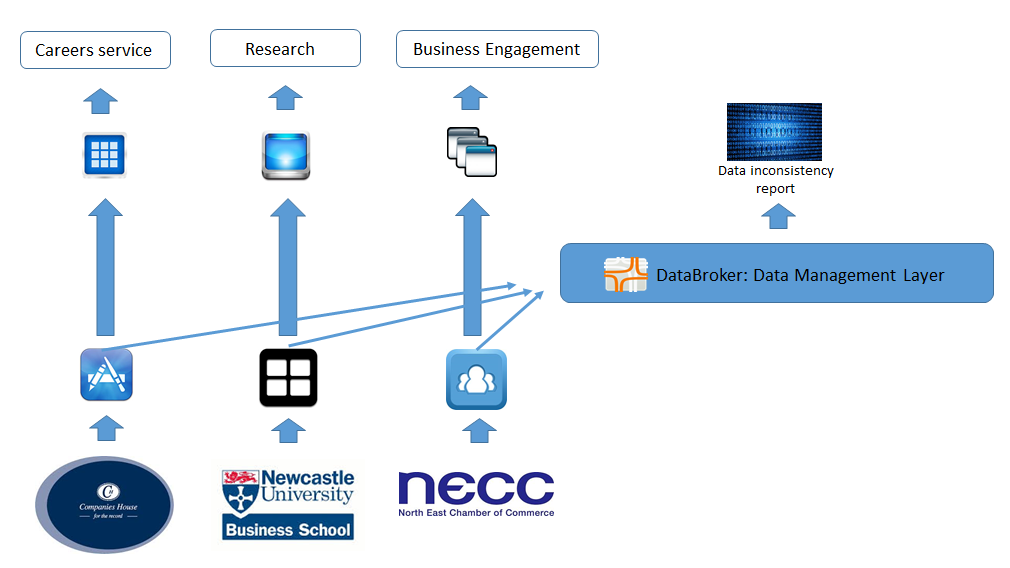
The introduction of Agility DataBroker and the publication of the ‘Data Inconsistency Report’ was a relatively simple process which required minimal effort and no disruption to the existing systems. However, this first step did little to address the fundamental inefficiencies caused by the existence of multiple application silos. Addressing these issues requires a further series of incremental steps by which Agility DataBroker would be extended so as to deliver the data collected directly to each of the applications delivering information to users. Once this has been achieved, the means of collecting and storing the data can be rationalised so that duplication and inconsistencies can be removed.
This solution also allows the data to be made available to other applications and therefore encourages the creation of new innovative services as well as improving the efficiency of existing ones.
The eventual, intended architecture is illustrated below.
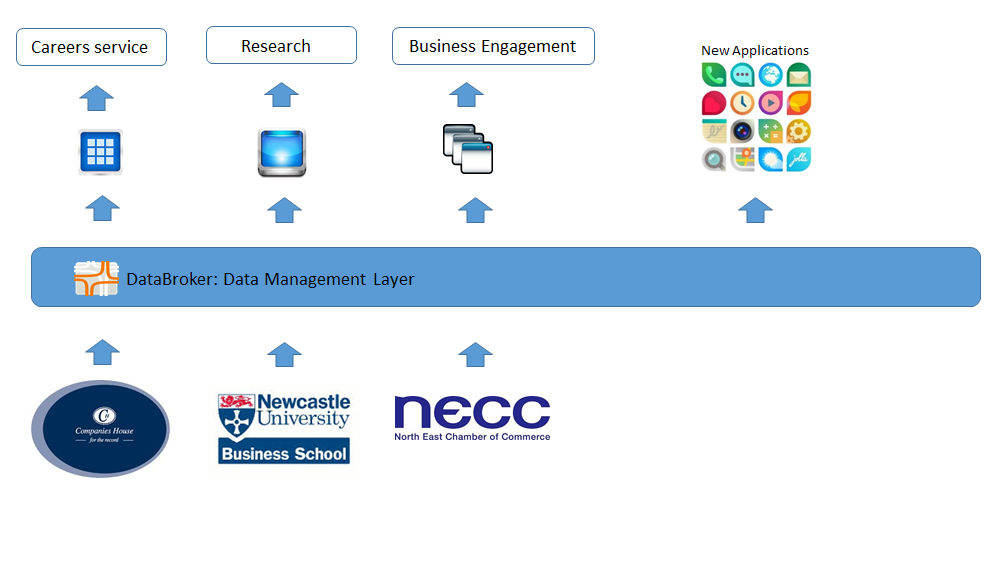
The project illustrates the problems with allowing data to be consigned to application silos and the advantages of introducing a Data Management Layer. In this case the introduction of Agility DataBroker enables the inefficiencies in data collection and storage to be removed, and the ability to deliver the data in multiple outputs opened up new opportunities to share the data within the organisation and beyond. Sharing the data and combining it with other data allows new information to be obtained with the potential to improve decision making, thereby reducing costs and/or improving service.
Agility DataBroker was introduced without impacting upon other applications and it should be clear that a step by step expansion in order to consume additional data would continue to provide additional benefits. In fact with data, the total exceeds the sum of the parts, as adding more data sets increases exponentially the number of ways in which data can be combined. In addition Agility DataBroker is capable of delivering transformed data in whatever format is required. This opens up the opportunity to deliver data to both internal and external application developers in order to encourage innovation, and to citizens and improve access to Council information.


